
Editor's note: This is the second post in our ongoing series on data management. The introduction can be found here, and part 1 on the Data Lifecycle here.
By Nicole Kaplan
In my previous post, I started this Data Lifecycle series by answering two questions. The first: what is the data lifecycle? The second: what key questions should a scientist ask to make his or her data openly accessible?
In today's post I will focus on the best starting place for good data management- making a plan!- and answer the question: what needs to be included in a data management plan?
It is always proposal-writing season in ecology. A proposal with research questions and a plan for answering them should also include a description of the data that will be collected and how they will be analyzed. Specifically, what data products will be produced in addition to the research results? Funding agencies, such as NSF and NASA, expect scientists to publish their research results and produce their research data as free, digital information. At this point, you may be asking yourself, did she just say free open access to my data? Yes! The expectation is that data are made freely available and open to the public for re-use in science, to bring transparency to the scientific process, ensure repeatability of results, and help to accelerate the synthesis of new ideas and knowledge about the world around us. These are high expectations from the research funders, and satisfying these expectations – to make data available - starts with a good plan!
The expectation [from NSF and NASA, etc] is that data are made freely available and open to the public for re-use in science, to bring transparency to the scientific process, ensure repeatability of results, and help to accelerate the synthesis of new ideas and knowledge about the world around us.
Planning to ultimately package data product(s), means beginning with an outcome in mind. One approach is to think about how data work fits in with the Data Life Cycle. The data life cycle was first developed for researchers in information science at the Digital Curation Center to accommodate the workflows and issues involved with curating, accessing and re-using digital objects (Higgins 2008). The life cycle has been adapted to identify the steps in a research process and highlight where additional data work can be applied according to best practices. Planning ahead will increase the chances of the data being useful in the future. Though the Data Life Cycle is illustrated as an iterative process, it all starts with a good plan!
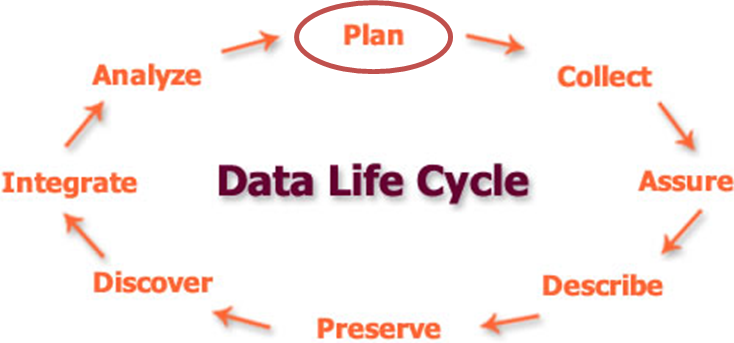
Scientists collect various types of information with the goals of analyzing, visualizing, and sharing results. Good management of data, or even samples from the field or lab, will facilitate steps in the data life cycle and allow you to share data in support of your results. Much like we document methods for collecting data in the field, manipulating and analyzing samples in the lab, and/or processing data through computational models, there are approaches and methods that need to be documented for managing data. These approaches and methods should be included in a data management plan.
What to include in a data management plan:
- Describe the types of data and their formats. Ask yourself: what is it you are going to manage and produce? What data will you need to answer your research question or test your hypothesis? What forms will that information come in?
- Create documentation about your data (this is also known as 'metadata'). Ask yourself: what will I need to know to use these data again or share it with a colleague? Identify a standard in use by the community or repository (Ecological Metadata Language [EML], Dublin Core, Darwin Core, see previous post).
- Consider the following as minimum documentation:
- Include a dataset title, an author’s name, contact information, and keywords.
- Write a descriptive abstract, which includes who, what, where, when, how, and why data were collected.
- Describe or provide references for methods and/or experimental designs.
- Create a list of attributes in the dataset.
- Provide descriptions and units for column header names (attributes) in tabular data.
- Define codes when necessary (e.g. LABU = Lark Bunting or F = gender of female).
- State the policies for re-use and attribution of your data products, and provide a persistent identifier and citation when possible. When publishing your results, be sure to determine if the publisher will require the data to be accessible in an online repository or if you will require permission from the publisher to distribute your data as a product of your research. Ask yourself if you need an embargo period to release your data until your findings are published or if your data are considered sensitive, i.e., do they contain information on human subjects or locations for a species of concern.
- Describe the cyber-infrastructure (CI) within your lab or group that provides software, hardware, and expertise for your data work. Include details on storage, back-up strategies, how users collaborate over the CI, and who facilitates or supports the work. Consider who can help prepare the data for open access and where it will be delivered. Identify and describe a centralized data management system for sharing and depositing data (e.g., office or individual workstation, cloud server, online system). Identify possible repositories or data centers that may be interested in preserving data for the long-term (http://databib.org/).
- Do not forget to include a budget! Keep the data plan simple, and seek expert support and/or training when you need it.
There are free tools online to help plan for data management, including the Data Management Planning (DMP) Tool (https://dmptool.org). Be sure to identify specific requirements articulated in the RFP, or by the agency or directorate.
DataONE. 2014a. Data Lifecycle Best Practices. DataONE, https://www.dataone.org/best-practices.
Higgins, S. (2008). The DCC curation lifecycle model. International Journal of Digital Curation, 3(1), 134-140.
Nicole Kaplan is a data manager at the Natural Resource Ecology Laboratory.
Featured image courtesy of Marina Noordegraf via Flickr under a Creative Commons Attribution-NonCommercial-ShareAlike 2.0 Generic License